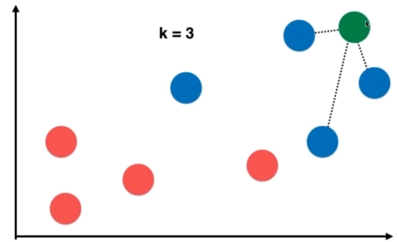
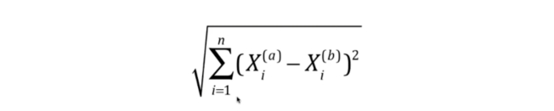KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归(预测)
KNN通过测量不同特征值之间的距离来进行分类但它通常用作分类算法
1. 诺贝尔奖官方网站: https://www.nobelprize.org/
2. 学术论文库: https://arxiv.org/
3. 算法库: https://leetcode.cn/
4. 数学可视化: https://www.geogebra.org/
5. 下面通过一个通俗易懂的例子来解释K近邻算法(K-Nearest Neighbors, KNN)
假设你是一个水果摊的小贩,你想根据水果的颜色和大小来判断一种新水果是苹果还是橙子。
你有一些已经标注好的水果样本,比如一些苹果和橙子,并且你知道它们的颜色和大小
1. 数据收集
你有以下标注好的水果样本:
苹果1: 红色,小
苹果2: 红色,中等
苹果3: 绿色,中等
橙子1: 橙色,大
橙子2: 橙色,中等
橙子3: 橙色,小
2. 数据表示
你可以把这些水果的数据表示成二维坐标:
苹果1:(红色,小)
苹果2:(红色,中等)
苹果3:(绿色,中等)
橙子1:(橙色,大)
橙子2:(橙色,中等)
橙子3:(橙色,小)
3. 新的水果
现在,你拿到一个新水果,你不知道它是苹果还是橙子,但你知道它的颜色是红色,大小是中等。你希望通过现有的水果样本来判断它的类别
4. K近邻算法步骤
计算距离:你计算新水果与所有已知水果的“距离”(在这个例子中,可以简单地理解为相似度)。对于颜色和大小,你可以设定一些规则来衡量它们的差异
红色和红色: 距离0
红色和橙色: 距离1
小和中等: 距离1
中等和中等: 距离0
大和中等: 距离1
找到最近的K个邻居: 假设K=3,你找到与新水果距离最近的三个邻居。通过计算,红色中等的水果距离苹果2、橙子2和橙子1最近
投票:查看这三个最近邻居的类别:
苹果2:苹果
橙子2:橙子
橙子1:橙子
其中两个邻居是橙子,一个邻居是苹果
分类:根据投票结果,多数类别是橙子,因此你判断这个新水果是橙子
1. 先上数学公式: 欧拉距离, 具体公式推导有兴趣可以自行百度这里为了让大家简单理解不探究太深的数学原理
1. 欧拉距离数学公式装换成Python代码
distances = []
for _train in x_train:
# 这个就是 欧氏距离的公式,求出的是一个新的点 对其他点的距离
d = sqrt(np.sum((_train - x)**2))
distances.append(d)
2. 手动实现KNN算法分类例子
import numpy as np
from collections import Counter
# 创建一个简单的数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [6, 5], [7, 8], [8, 8]])
# 用与给数据集分类的便签类型
y_train = np.array([0, 0, 0, 1, 1, 1])
# 创建将要预测分类的新值
X_test = np.array([3, 6])
# 设置k值
k = 3
# 存放距离的列表
distances = []
# 使用 欧式距离公式 计算
for x_train in X_train:
distance = np.sqrt(np.sum((X_test - x_train) ** 2))
distances.append(distance)
# 将距离转换为numpy数组以便后续操作
distances = np.array(distances)
print(distances) # [4.47213595 3.16227766 2. 3.16227766 4.47213595 5.38516481]
# 按距离排序 并获取前k个最近邻的索引
k_indices = np.argsort(distances)[:k]
print(k_indices) # [2 1 3]
# 提取前k个最近邻的分类标签, 也就是k=3
k_nearest_labels = [y_train[i] for i in k_indices]
print(k_nearest_labels) # [0, 0, 1]
# 统计每个标签出现的频率
most_common = Counter(k_nearest_labels)
print(most_common) # Counter({0: 2, 1: 1})
# most_common(1) 意思是:用于返回出现次数最多的元素及其次数, [0][0] 意思是:通过索引取值
predictions = most_common.most_common(1)[0][0]
# 输出预测结果
print(predictions) # 该类别属于第: 0 类
3. sklearn框架中实现kNN分类算法
下载包: pip3 install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 创建一个简单的数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [6, 5], [7, 8], [8, 8]])
# 用与给数据集分类
y_train = np.array([0, 0, 0, 1, 1, 1])
# 创建将要预测分类的新值
X_test = np.array([[3, 6]])
# 设置k值
k = 3
# 实例化KNeighborsClassifier,并设置k值(底层就是调用了距离公式)
knn = KNeighborsClassifier(n_neighbors=k)
# 使用训练数据拟合模型
knn.fit(X_train, y_train)
# 对测试数据进行预测
predictions = knn.predict(X_test)
# 输出预测结果
print(predictions) # 该类别属于第: 0 类
4. 手动实现KNN算法预测例子
import numpy as np
from collections import Counter
# 创建一个简单的数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [6, 5], [7, 8], [8, 8]])
y_train = np.array([1.5, 2.5, 3.5, 5.0, 7.0, 8.0]) # 连续值标签,用于回归(预测)任务
X_test = np.array([3, 3])
# 设置k值
k = 3
# 初始化预测结果列表
predictions = []
distances = []
for x_train in X_train:
# 计算欧拉距离
distance = np.sqrt(np.sum((X_test - x_train) ** 2))
distances.append(distance)
# 将距离转换为numpy数组以便后续操作
distances = np.array(distances)
# 按距离排序并获取前k个最近邻的索引
k_indices = np.argsort(distances)[:k]
# 提取前k个最近邻的标签
k_nearest_labels = [y_train[i] for i in k_indices]
# 计算前k个标签的平均值,作为预测结果
prediction = np.mean(k_nearest_labels)
# 将预测结果加入预测结果列表
predictions.append(prediction)
# 输出预测结果
print(predictions) # 输出预测结果 [2.5]
5. sklearn框架中实现kNN预测算法
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
# 创建一个简单的数据集
X_train = np.array([[1, 2], [2, 3], [3, 4], [6, 5], [7, 8], [8, 8]])
y_train = np.array([1.5, 2.5, 3.5, 5.0, 7.0, 8.0]) # 回归任务中的连续数值标签
X_test = np.array([[3, 3]])
# 设置k值
k = 3
# 实例化KNeighborsRegressor,并设置k值
knn_reg = KNeighborsRegressor(n_neighbors=k)
# 使用训练数据拟合模型
knn_reg.fit(X_train, y_train)
# 对测试数据进行预测
predictions = knn_reg.predict(X_test)
# 输出预测结果
print(predictions) # 输出预测结果,例如: [2.5]
KNN 算法的核心思想是基于距离来进行分类或预测。对于给定的输入实例,它会查找训练集中与之距离最接近的 K 个实例(即“邻居”),
然后通过这些邻居的信息来进行分类或预测
scikit-learn官网: https://scikit-learn.org/stable/user_guide.html