训练:
Windows
支持 CUDA 的 nVIDIA 显卡,每张拥有至少 8G 以上显存
常见的不能使用的显卡:2060以前所有显卡
Windows 10/11 系统
如果没显卡的话会自动识别使用CPU训练,但会很慢
推理:
Windows
支持 CUDA 的 nVIDIA 显卡,每张拥有至少 4G 以上显存(未实测,3G刚好无法合成一句,所以推测4G应该可以)
Windows 10/11 系统
如果没显卡的话会自动识别使用CPU推理,但会很慢
温馨提示:笔记本用户请做好散热!已经有人训练时不注意发生了火灾!训练会同时吃满CPU和GPU!
比打游戏的压力大很多!请千万做好散热!安全第一!如果散热开口在下面的请将笔记本悬空!
长期训练记得及时更换硅脂。 不要在无人的时候训练!如果训练后电脑出现任何硬件问题概不负责!
--进入后点击 “中文简体“
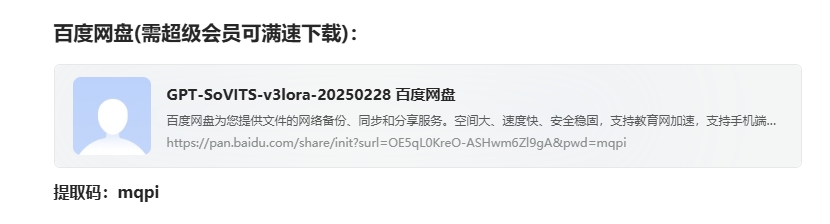
--推荐选择使用百度网盘下载
--等待下载完成
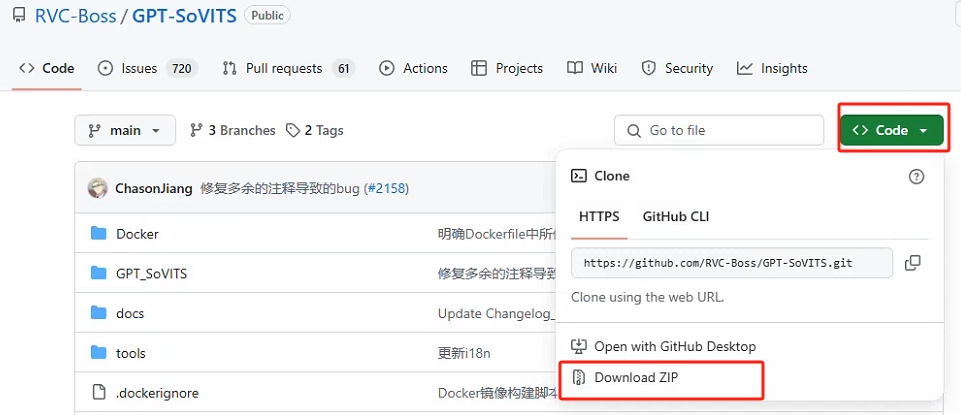
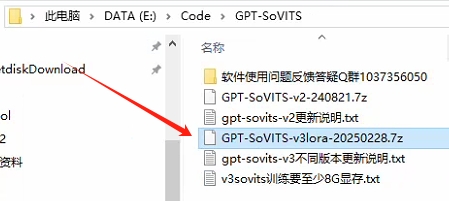
--下载GitHub开源包(注意开源包里面不包含环境,可以不下载)
--解压整合包
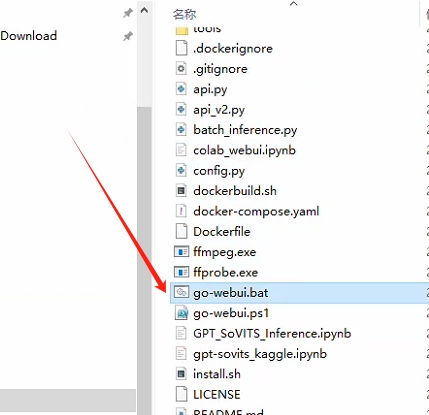
--解压完成后运行文件夹中的 go-webui.bat
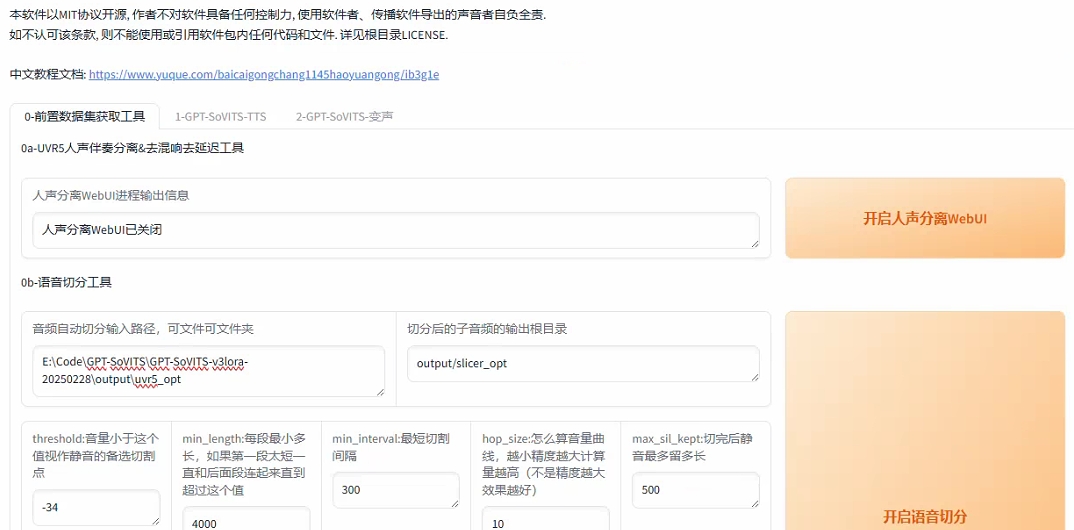
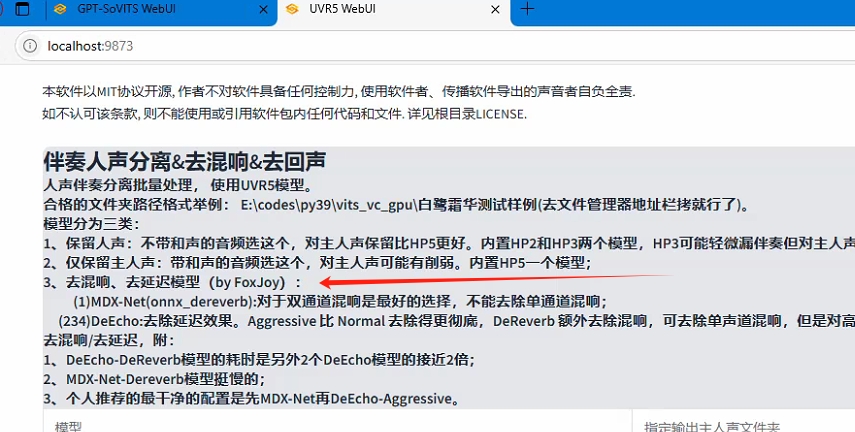
--根据网页提示选择合适的分离模型
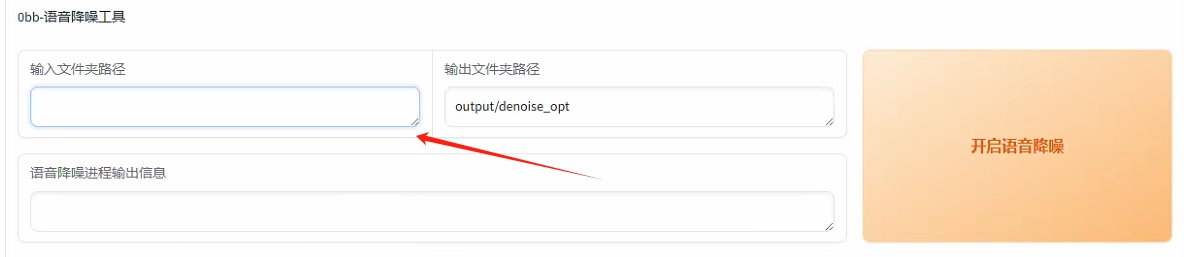
--降噪这块输入文件夹路径点击降噪即可
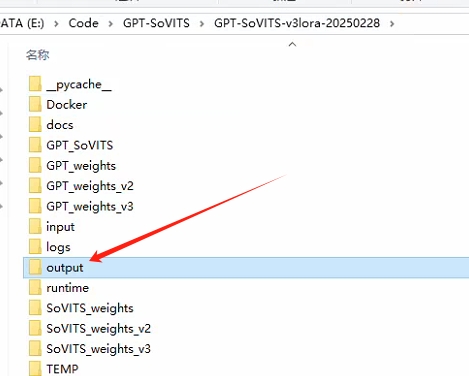
--注意所有处理好的文件都在output文件夹中,确认好没有杂音和混响后进行下一步
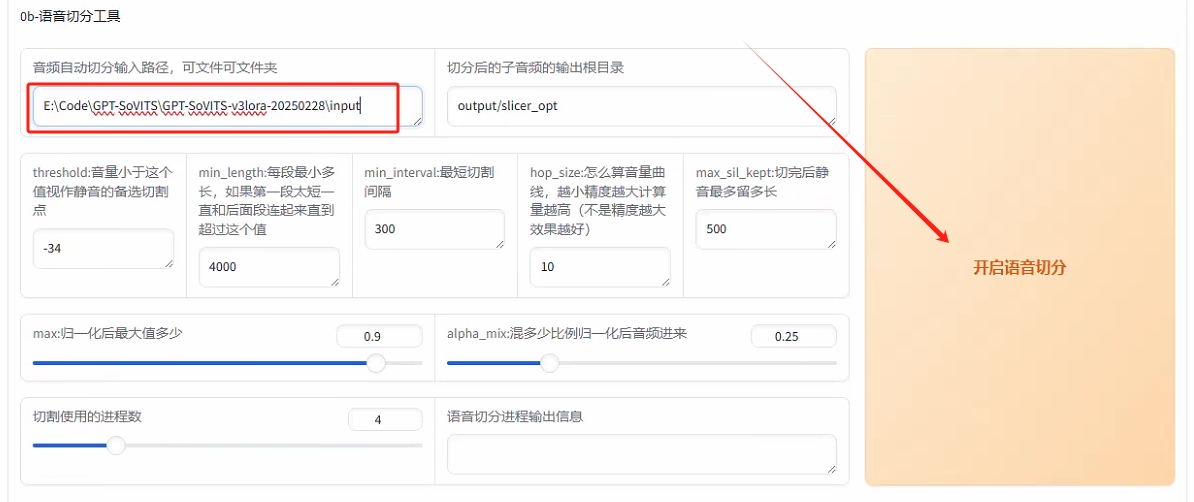
--输入路径点击“开启语音切分”
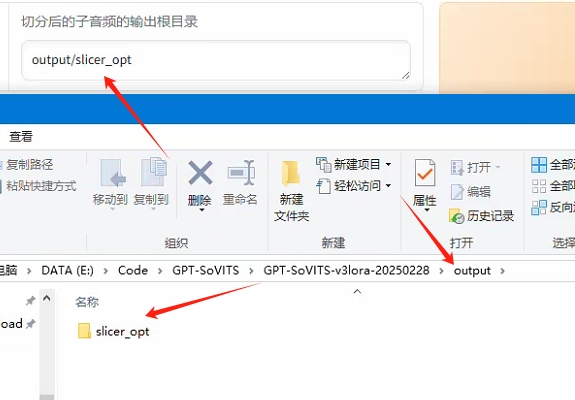
--切分后路径
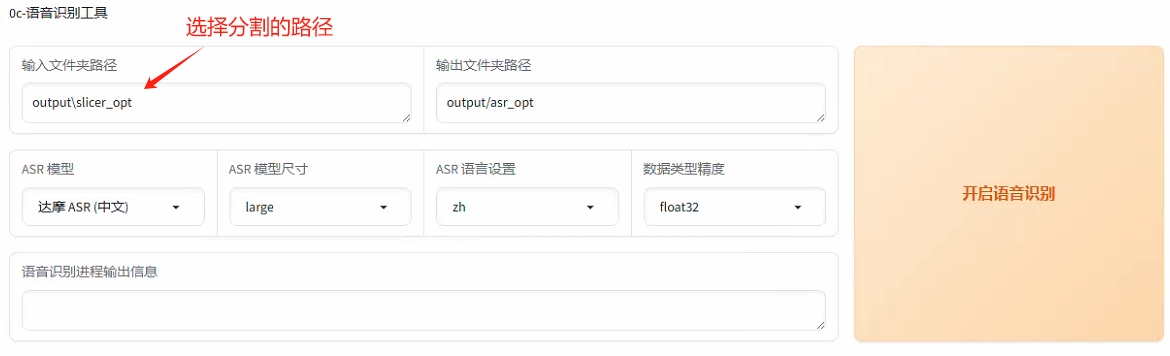
--输入切分后的路径点击“开启语音识别”
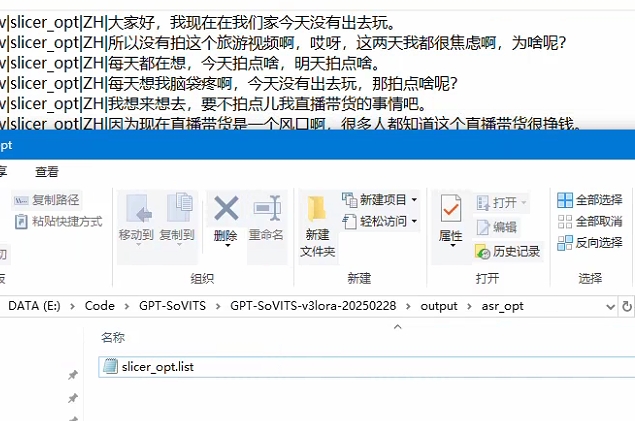
--语音识别后打开生成的slicer_opt.list 文件确认识别的文字是否正确
--如果识别的不准确修改文字后点击“开启音频标注”音频识别正确可跳过
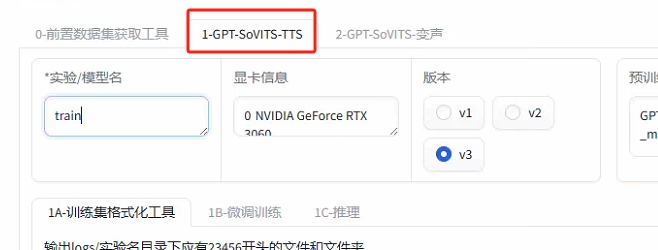
--接下来点击 “GPT-SoVITS-TS” 切换页面
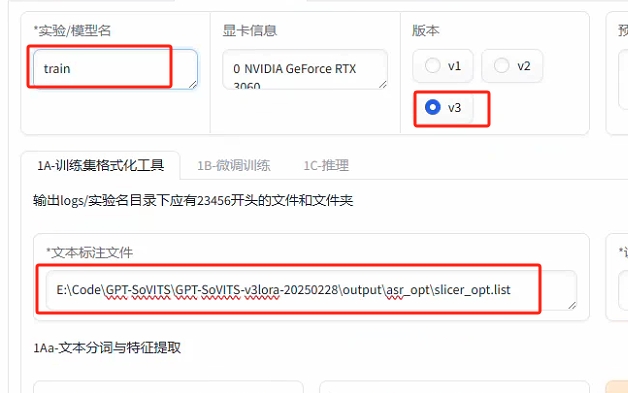
--选择模型名称,版本,标注文件
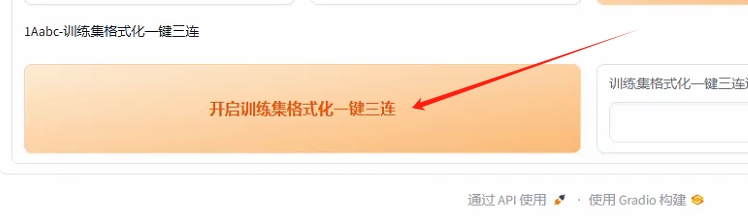
--点击“开启训练集格式化一键三连”
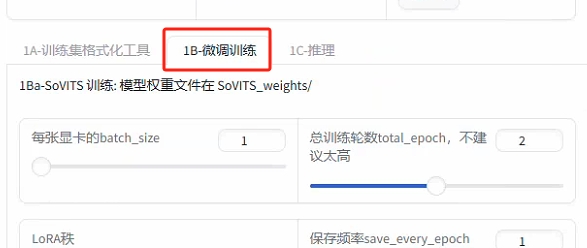
--切换到微调模型
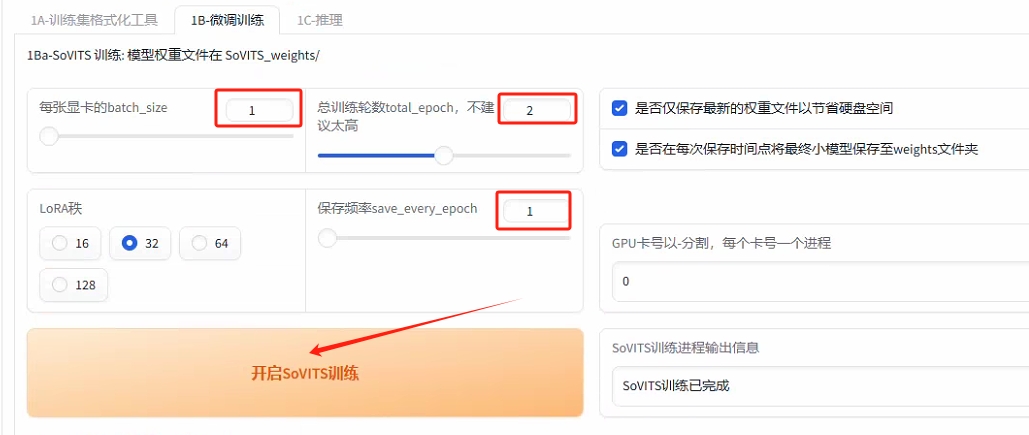
--选择合适的配置点击“开启SoVITS训练”
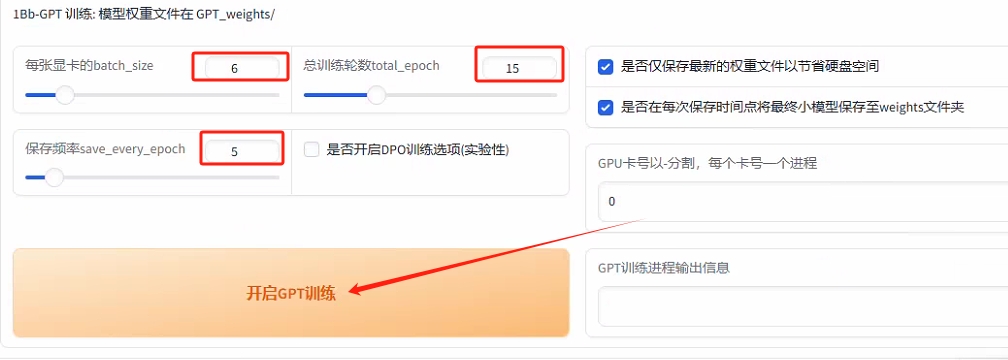
--选择合适的配置点击“开启GPT训练”, 注意两个不要同时开启训练
--GPT_weights 和 SoVITS_weights分别在不同文件夹
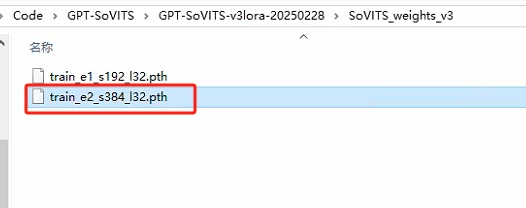
--找到SoVITS_weights训练最后一轮的模型权重文件
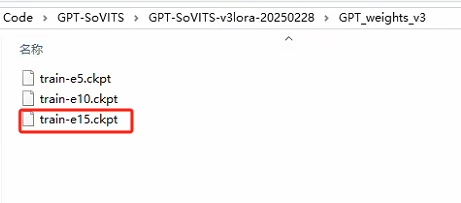
--找到GPT_weights训练最后一轮的模型权重文件
至此模型标注训练完成
.pth文件作用
主要用于存储SoVITS模型的权重。是语音转换模型,它能够将一种语音风格转换为另一种风格,同时保持语音的自然度和清晰度。
GPT-SoVITS框架中,SoVITS模型负责生成最终的音频文件,因此其权重对于合成语音的质量至关重要。
.ckpt文件作用
.ckpt文件则用于存储GPT模型的权重。GPT是一个基于Transformer架构的预训练语言模型,它能够生成自然流畅的文本。
在GPT-SoVITS框架中,GPT模型负责生成文本特征,这些特征随后被用于指导SoVITS模型生成语音。
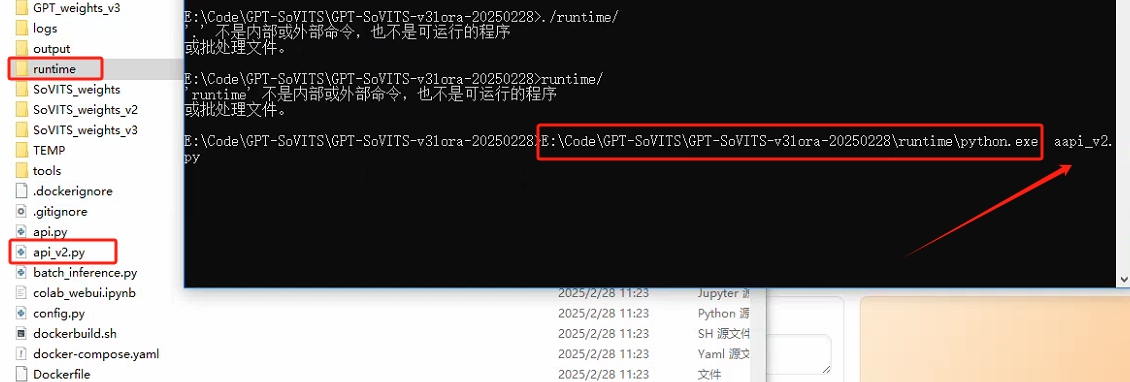
--打开整合包文件目录
--runtime: 文件夹是Python环境目录
--api.py和api_v2.py: GPTSoVITS接口服务一般用api_v2.py
--启动GPTSoVITS接口服务,使用runtime文件夹中的Python环境执行 api_v2.py
--终端出现以下文字表示服务启动成功
GET:
```
http://127.0.0.1:9880/tts?text=先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。&text_lang=zh&ref_audio_path=archive_jingyuan_1.wav&prompt_lang=zh&prompt_text=我是「罗浮」云骑将军景元。不必拘谨,「将军」只是一时的身份,你称呼我景元便可&text_split_method=cut5&batch_size=1&media_type=wav&streaming_mode=true
```
POST:
```json
{
"text": "", # (必需)要合成的文本
"text_lang: "", # (必需)要合成的文本的语言
"ref_audio_path": "", # (必需)参考音频路径 10秒内
"aux_ref_audio_paths": [], # (可选)用于多扬声器音调融合的辅助参考音频路径
"prompt_text": "", # (可选)参考音频的提示文本
"prompt_lang": "", # (必需)参考音频提示文本的语言
"top_k": 5, # 最高k抽样
"top_p": 1, # 顶部p取样
"temperature": 1, # 取样温度
"text_split_method": "cut0", # 文本拆分方法,详见text_segmentation_method.py
"batch_size": 1, # 推断的批量大小
"batch_threshold": 0.75, # 批量拆分的阈值
"split_bucket: True, # 是否将批分割为多个时段
"speed_factor":1.0, # 控制语速数值越大声音越快
"streaming_mode": False, # 是否返回流响应
"seed": -1, # 随机种子的再现性
"parallel_infer": True, # 是否使用平行推断
"repetition_penalty": 1.35 # T2S模型的重复惩罚
}
```
RESP:
成功: 直接返回 wav 音频流, http code 200
失败: 返回包含错误信息的 json, http code 400
# Python 调用示例:
import requests
def GetGPTSoVITSData(url, data, output_path):
"""
调用GPTSoVITS克隆推理接口
url: 调用的接口地址
data: 请求的参数
output_path: 音频保存的路径
"""
with requests.post(url, json=data,stream=True) as response:
# 检查请求是否成功
if response.status_code == 200:
# 以二进制写模式打开文件
with open(output_path, 'wb') as file:
# 循环读取响应内容,每次读取一个块
for chunk in response.iter_content(chunk_size=1024):
# 如果chunk存在(即不是None),则将其写入文件
if chunk:
file.write(chunk)
url = "http://127.0.0.1:9880/tts"
data = {
"text": "先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也",
"text_lang": "zh",
"ref_audio_path": "E:/Code/OcrUITool/1.wav",
"aux_ref_audio_paths": [],
"prompt_text": "这些都需要进行自我解剖,自我批评。所谓慎独,是指一个人在独处无人监督的情况下。",
"prompt_lang": "zh",
"top_k": 5,
"top_p": 1,
"temperature": 1,
"text_split_method": "cut0",
"batch_size": 1,
"batch_threshold": 0.75,
"split_bucket": True,
"speed_factor":1.0,
"streaming_mode": False,
"seed": -1,
"parallel_infer": True,
"repetition_penalty": 1.35,
"media_type":"wav"
}
GetGPTSoVITSData(url, data, "2.wav")
--Python调用重启服务/停止服务接口示例
GET:
```
http://127.0.0.1:9880/control?command=restart
```
POST:
```json
{
"command": "restart"
}
```
RESP: 无
# Python 调用重启服务模型示例:
import requests
def RestartGPTSoVITS(url):
"""
重启服务或停止服务接口
url: 调用的接口地址
"""
response = requests.get(url)
print(response.text)
url = "http://127.0.0.1:9880/control?command=restart" # command=restart 重启服务,command=exit 结束运行
RestartGPTSoVITS(url)
--切换GPT模型和Sovits模型
### 切换GPT模型
endpoint: `/set_gpt_weights`
GET:
```
http://127.0.0.1:9880/set_gpt_weights?weights_path=GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt
```
RESP:
成功: 返回"success", http code 200
失败: 返回包含错误信息的 json, http code 400
### 切换Sovits模型
endpoint: `/set_sovits_weights`
GET:
```
http://127.0.0.1:9880/set_sovits_weights?weights_path=GPT_SoVITS/pretrained_models/s2G488k.pth
```
RESP:
成功: 返回"success", http code 200
失败: 返回包含错误信息的 json, http code 400
# Python 调用切换GPT模型示例:
import requests
def SetGpt(url):
"""
切换GPT模型
url: 调用的接口地址
"""
response = requests.get(url)
print(response.text)
url = "http://127.0.0.1:9880/set_gpt_weights?weights_path=E:/Code/GPT-SoVITS/GPT-SoVITS-v3lora-20250228/GPT_weights_v3/train-e15.ckpt"
SetGpt(url)
# Python 调用切换Sovits模型示例:
import requests
def SetSovits(url):
"""
切换Sovits模型
url: 调用的接口地址
"""
response = requests.get(url)
print(response.text)
url = "http://127.0.0.1:9880/set_sovits_weights?weights_path=E:/Code/GPT-SoVITS/GPT-SoVITS-v3lora-20250228/SoVITS_weights_v3/train_e3_s576_l32.pth"
SetSovits(url)