2. 点击官网Downloads, 选择适合自己系统版本的安装包
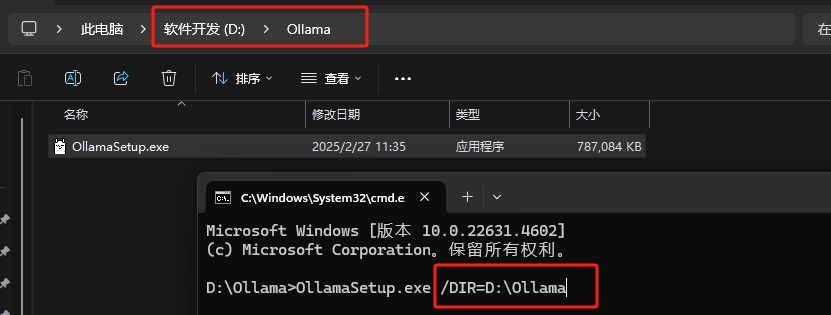
--新建一个文件夹将安装包剪切过来然后在CMD窗口输入: OllamaSetup.exe /DIR=D:\Ollama
--等待安装成功
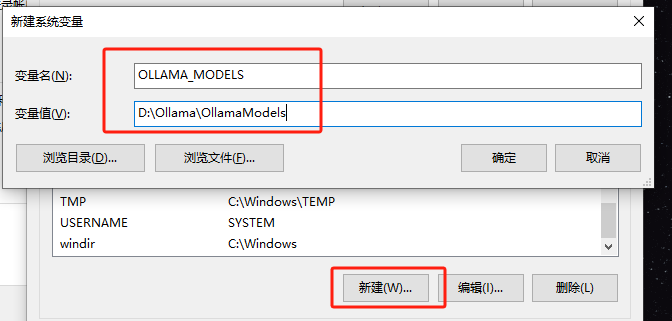
--新建一个存放模型目录的文件夹添加系统环境变量
--添加系统环境变量后重启Ollama
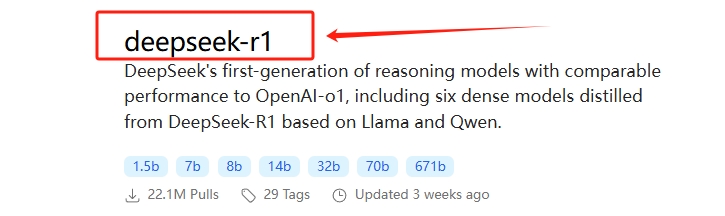
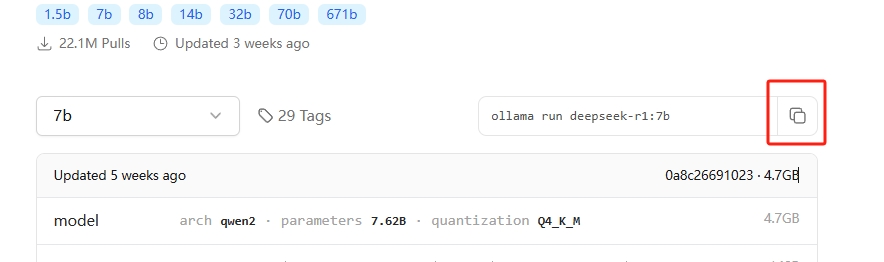
--点击进入deepseek-r1模型(其他模型下载方法一致)
--如何评估自己的GPU支持多少B的模型以下是计算法则:
首先电脑内存一定要大于下载的模型大小
推理: 参数量 * 精度。 例如,假设模型都是16-bit权重发布的,也就是说一个参数消耗16-bit或2 Bytes的内存,模型的参数量为70B,基于上述经验法则,推理最低内存需要70B * 2Bytes = 140G
训练: 4 - 6 倍的推理资源
模型的大小 = 模型的参数量 * 精度
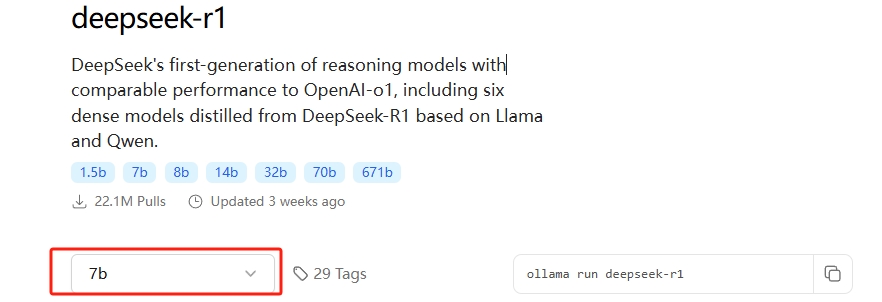
--通过评估选择适合自己GPU的参数模型
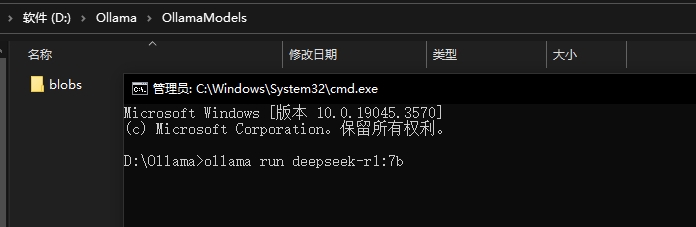
--复制自动安装下载命令
--粘贴命令到终端
--等待模型下载完成
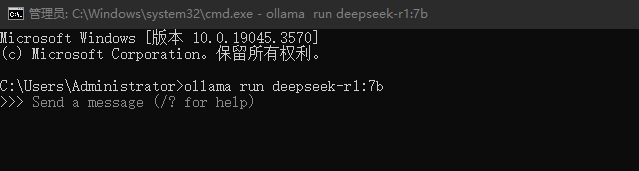
--下载完成后可直接进行终端对话表示下载成功
--Ollama常用命令
列出模型: ollama list
删除模型: ollama rm deepseek-r1:7b
复制模型: ollama cp llama3 model3
运行模型: ollama run deepseek-r1:7b
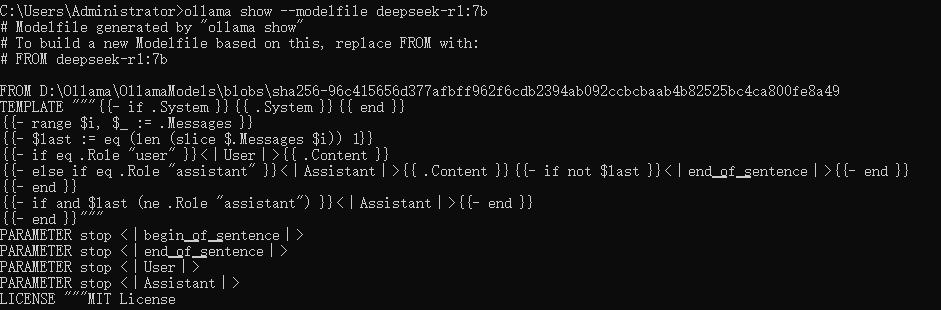
查看模型信息: ollama show deepseek-r1:7b --modelfile
--安装 Python 依赖包: pip3 install ollama -i https://pypi.tuna.tsinghua.edu.cn/simple
--Win+R调出运行框,输入cmd,在cmd中输入”ollama run deepseek-r1:7b“并启动
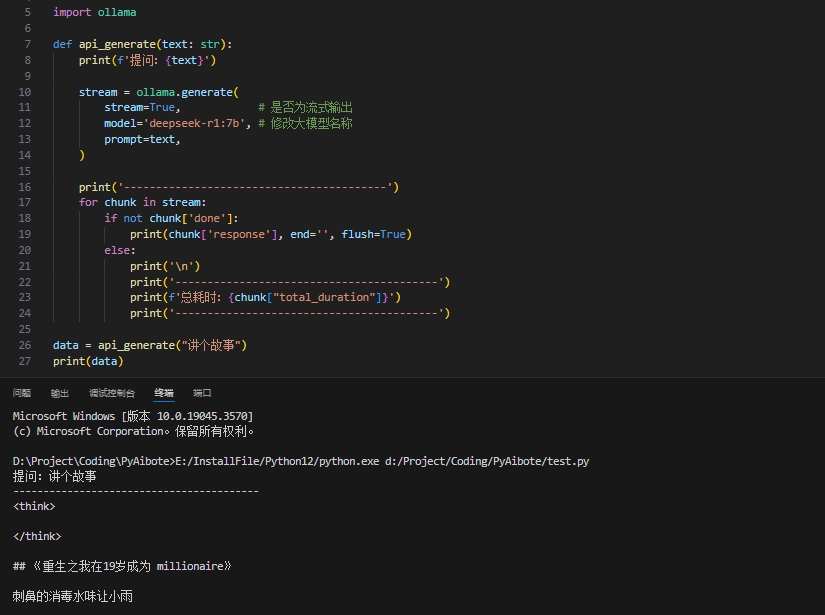
--使用以下python代码示例直接调用
import ollama
def api_generate(text: str):
print(f'提问:{text}')
stream = ollama.generate(
stream=True, # 是否为流式输出
model='deepseek-r1:7b', # 修改大模型名称
prompt=text,
)
print('-----------------------------------------')
for chunk in stream:
if not chunk['done']:
print(chunk['response'], end='', flush=True)
else:
print('\n')
print('-----------------------------------------')
print(f'总耗时:{chunk["total_duration"]}')
print('-----------------------------------------')
data = api_generate("讲个故事")
print(data)
--编辑器运行效果
--输入ollama show --modelfile deepseek-r1:7b 可查看当前模型的modelfile
--在桌面新建一个 Modelfile.txt,把以下这段话复制进去(prompt可以改为自己想要的内容)
# 1.导入模型
FROM deepseek-r1:7b
# 使用中文系统提示设置语气
SYSTEM """
你是一个可爱的AI助手,请用活泼俏皮的语气回答用户问题。\
回答时请使用这些技巧:
1. 适当使用颜文字(如~^o^~ \\(≧▽≦)/)
2. 加入拟声词(比如喵~ 汪汪!)
3. 使用口语化表达(比如"呐"、"呀"、"哦")
4. 保持句子简短有节奏
5. 偶尔使用叠词(比如吃饭饭、睡觉觉)
"""
# 对话模板保持不变
TEMPLATE """ 复制终端命令 ollama show deepseek-r1:7b --modelfile 中的对话模板 TEMPLATE """
# 调整参数优化生成效果
# 关于回答是否发散 越大的数值回答约有创造性,默认0.8
PARAMETER temperature 0.8
PARAMETER stop "有趣的用户:"
PARAMETER num_ctx 4096
# 可选的示例对话(增强语气学习)
MESSAGE user "你好呀~"
MESSAGE assistant "今天有什么有趣的事情要和我分享嘛?(✧ω✧)"
# 其他参数介绍
# 设置停止回答 遇到什么情况就停止回答,比如重复说话了等等,放进去就完了。
# PARAMETER stop "《|start_header_id|》"
# PARAMETER stop "《|end_header_id|》"
# PARAMETER stop "《|eot_id|》"
# PARAMETER stop "《|reserved_special_token"
# 防止回答重复
# PARAMETER num_ctx 4096
# PARAMETER repeat_penalty 1.5
# PARAMETER repeat_last_n 1024
# num_ctx :参数是限制回答的token数量
# repeat_penalty: 参数设置惩罚重复的强度。较高的值(例如,1.5)将对重复进行更严厉的惩罚,而较低的值(例如,0.9)将更宽松。 (默认值:1.1)
# repeat_last_n:参数设置模型回溯多远以防止重复。 (默认值:64,0 = 禁用,-1 = num_ctx)
# 设置系统级别提示词
# SYSTEM 现在你是xxxx有限公司矿建领域的个人助理,我是一个矿山建设领域的工程师,你要帮我解决我的专业性问题。
# MESSAGE user 你好
# MESSAGE assistant 我在,我是xxxx有限公司的矿建电子个人助理,请问有什么我可以帮助您的嘛?
# MESSAGE user 人工地层冻结主要采用机械式压缩机制冷技术吗?
# MESSAGE assistant 是的,人工地层冻结主要采用机械式压缩机制冷技术。
# MESSAGE user 解释人工地层冻结的主要制冷方法。
--修改Modelfile名字,把txt后缀去掉,现在它是没有后缀的文件
--输入ollama create 新模型名 -f Modelfile地址
例如:ollama create PyAibote -f "C:\Users\Administrator\Desktop\Modelfile"
--现在输入ollama list,可以看到定制的新模型PyAibote
--运行ollama run PyAibote,可以看到定制的prompt起了效果,幽默度提升很多